
In today’s world of microservices, NodeJS has become the go to runtime platform to build and deploy server applications on. It’s easier to implement, faster to integrate and to some extent manageable to scale. This specially catches the eyes of new startups who plan to deploy multitudes of microservices in a span of a few months.
While NodeJS is one of the top choices to build these servers, it definitely has its problems. NodeJS is *single threaded *(excluding the internals which might be using multiple threads like I/O operations). Now, I won’t be comparing performances here between single threaded and multi threaded servers as both have their pros and cons. And, as a matter of fact, NodeJS manages requests and resources very well using the concept of *single threaded event loop as can be seen by the fact that companies like Netflix, Paypal and Uber to name a few, use NodeJS.
The problem with reading request objects from anywhere Link to heading
Large microservices are usually built around a strong and streamlined architecture. Out of many things, this is done to maintain scalability. A strong architecture usually has multiple layers, which a request has to travel. This may include multiple middlewares, a controller and/or multiple services.
Now the problem that we are trying to solve here is a very common one. It’s to get our current request data from any of the aforementioned layers. In a usual MVC based application, we have access to our request object on the controller layer. This is true for any MVC based server be it a single threaded or multi threaded one. Now, obviously the first thing that comes to mind is this:
— Why not simply pass the request object down the layers? Link to heading
Infact, we can pass the request object as a function parameter down the layers. But this creates some other issues. For example:
- What about the separation of concerns for the service functions? Functions of the service shouldn’t have to be bound to the request object.
- What about Scalability? When you have a huge application with hundreds of controllers and services and a good number of developers working on them, it’s better not to dispose of such responsibilities to the developers.
- What about Performance and Resources? The more time an endpoint requires to execute, the more memory would be required by the server. This is because arguments that the function would go on to live for as long as the service function executes. And, having all of the request data for each concurrent request would be the worst case to be in.
Next thing that comes to mind is why not simply pass the required data from the request down the layers as parameters to the function? Well, this is even worse for the scalability part and will lead to bad code.
How multithreaded applications manage request context Link to heading
For servers based on multithreaded environments, this is actually not even a problem. That’s because multithreaded servers can create a new thread for each of the incoming requests and since each thread can have its own stack memory, each thread can contain the request object itself which exists as long as the thread lives.
Therefore, applications based on the Laravel framework for example, can access the request object from anywhere and it would provide the request data unique to the life of that request.
Why is this not a problem in single threaded applications? Link to heading
For a single threaded server, we cannot maintain the state of requests uniquely simply because all of the requests are handled in the same thread and hence there’s no globally unique context for a single request.
But thanks to the concept of event loop, this is now possible.
Back to Request Context… Link to heading
At this point, you must be wondering what does all this have to do with storing the request’s context?
Quite recently, NodeJS introduced the concept of “Async Hooks”. These hooks are basically events that track the lifetime of an asynchronous operation. This is an experimental feature which introduces some very important events that are triggered on multiple instances. These hooks are:
- init
- before
- after
- destroy
- promiseResolve
As the names suggest, these are triggered when an async resource is initialised, before it’s called, after it’s called and once it is destroyed. Let’s explore the API provided by Async Hooks and see how they can help us in making the request context globally available:
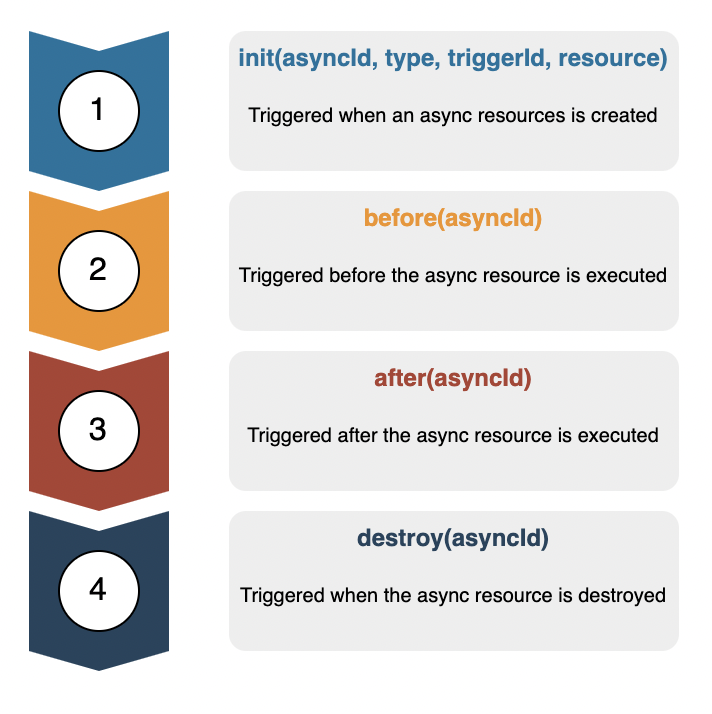
- An async resource can be a timeout, promise or an async function. For the full list of what types of async resources are hop over here.
The init event is triggered upon the creation of an async resource. The Async Hooks API assigns a unique asyncId to this resource. The type parameter is a string and defines the type of async resources as discussed before. The triggerId is the asyncId of the parent async resource that created this resource, it is 0 in case of first execution. The resource parameter is a reference to the async resource. - The before event is triggered before the async resource is used executed. This can be used to intercept the execution of the resource.
- The after event is triggered after the async resource is used executed. This can be used to perform any execution on the resource after its usage.
- The destroy event is triggered when the async resource is released. Any cleanup should be performed here.
— So, how can this be used to provide request context globally? Well, here’s how: Link to heading
- We can maintain a store, a Map, which will store the contexts of all the requests. The key to this map will be the unique asyncId provided by the init event. But there’s a problem with this. If an async function calls another async function, it will trigger the init event again which will give a new asyncId. But the triggerId will be the asyncId of the calling function. We can use this to check if a context already exists, only if it doesn’t, shall we add it to the store.
- We can then access it anywhere using the executionAsyncId() method provided by the Async Hooks API. This method returns the asyncId of the current async resource.
- Once the function returns, the destroy event is triggered with the asyncId. It is our job to remove the context of this asyncId from the store. This can be done here to ensure that there is no memory leak.
While this seems a lot to store the request context, it is actually pretty straight forward and can be done with a Singleton class. To make things easier, NodeJS also provides AsyncLocalStorage, a wrapper of all the implementation that we discussed above for Async Hooks.
Exploring AsyncLocalStorage… Link to heading
NodeJS exposes two important methods via the AsyncLocalStorage API:
- run(store, callback) is used to create a context for executions described in the callback block. The first argument takes a store that is unique to the context, this can be a map. The second argument takes the callback in which all other executions are performed.
- getStore() is used to get the store object provided by us in the call to run. It is important that this be called inside the callback function as that is the place where this store is unique. The store has 2 methods:
- get(key) which is used to get data stored at the specified key.
- set(key, value) which is used to set data on the specified key.
This makes it a lot simpler than Async Hooks. Also, as per the docs of NodeJS, this is preferred over Async Hooks for its performance benefits.
So much for request context? Link to heading
As far as request context is concerned, Async Hooks fulfil the need of a lot more use cases than just this.
Some examples of what can be done with Async Hooks other than storing request context include:
- Request Level Caching, to store temporary data that lives throughout the lifetime of the request and can be accessed anytime without the need of executing repeating operations.
- Tracing Errors ,In a huge product application, this is a must have. Async Hooks can help to track down errors across multiple microservices.
- Performance Monitoring, Async Hooks can be used to monitor the performance of an app. For example, it can be used to measure the number for hops an API took, or the number of times a recursive function was called.
And many more yet to be discovered…
Performance Impact Link to heading
As with the great benefits that Async Hooks provide, it also comes with a bit of a performance hit. This is where you have to make a trade-off. If the benefits that we discussed above outweighs the impact of performance for your use case, then this is a must have.
In one of our cases, we found the following performance metrics using wrk:
Note: These tests were performed on the same API.
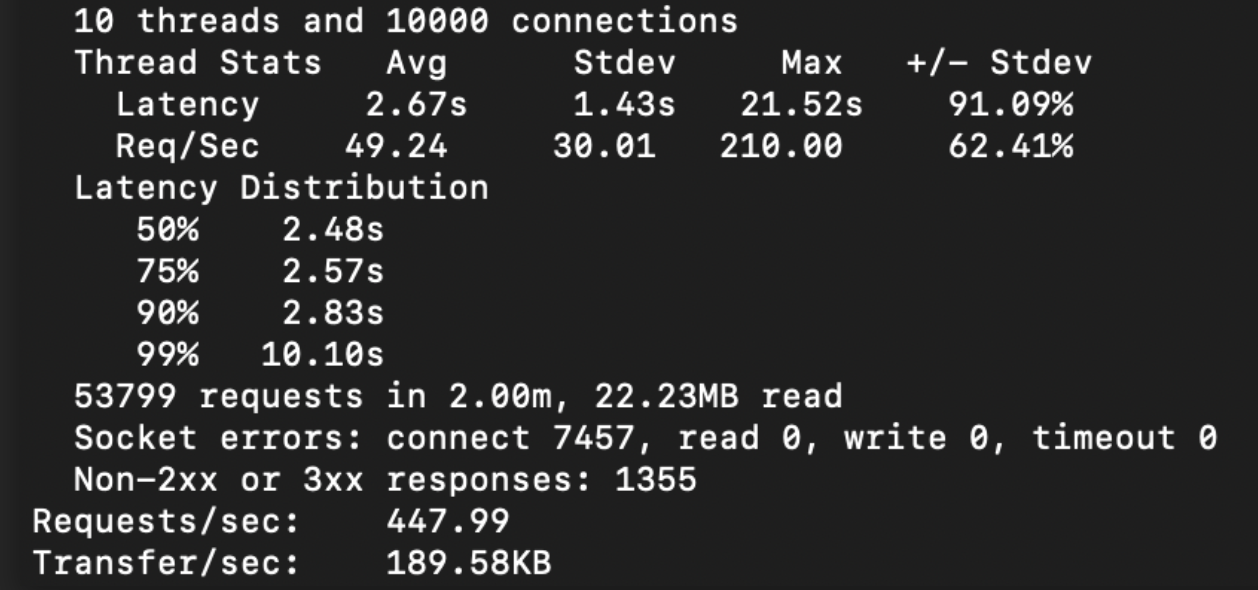 Without Async Hooks or Async Local Storage
Without Async Hooks or Async Local Storage
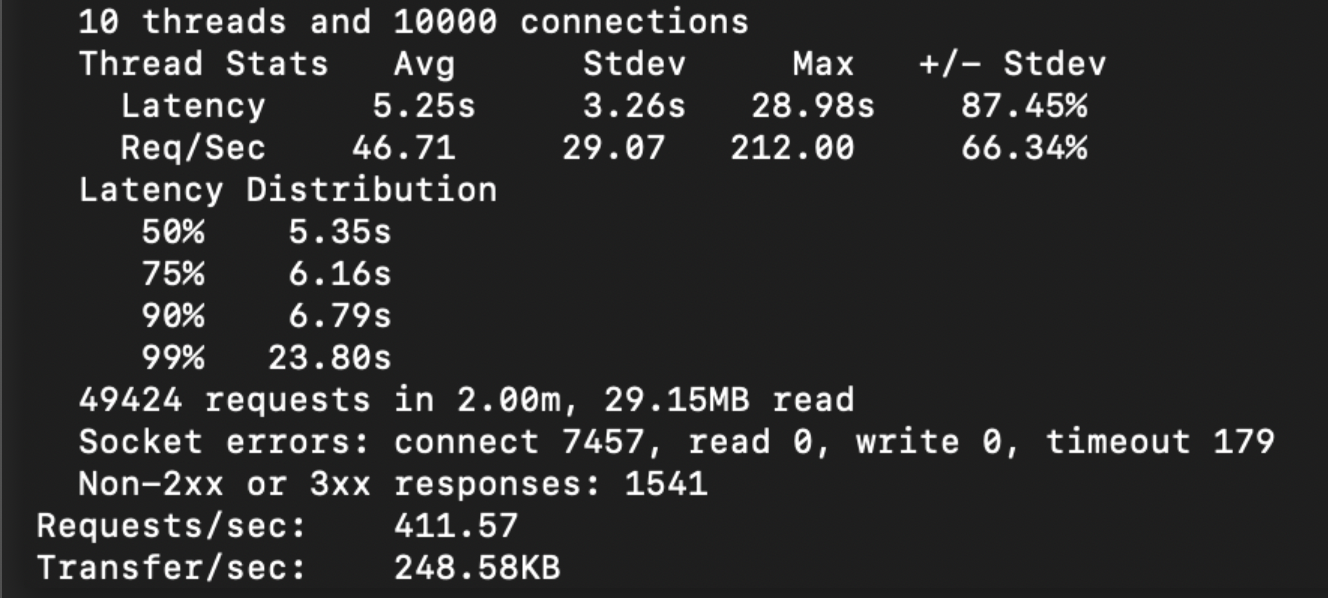 With Async Hooks
With Async Hooks
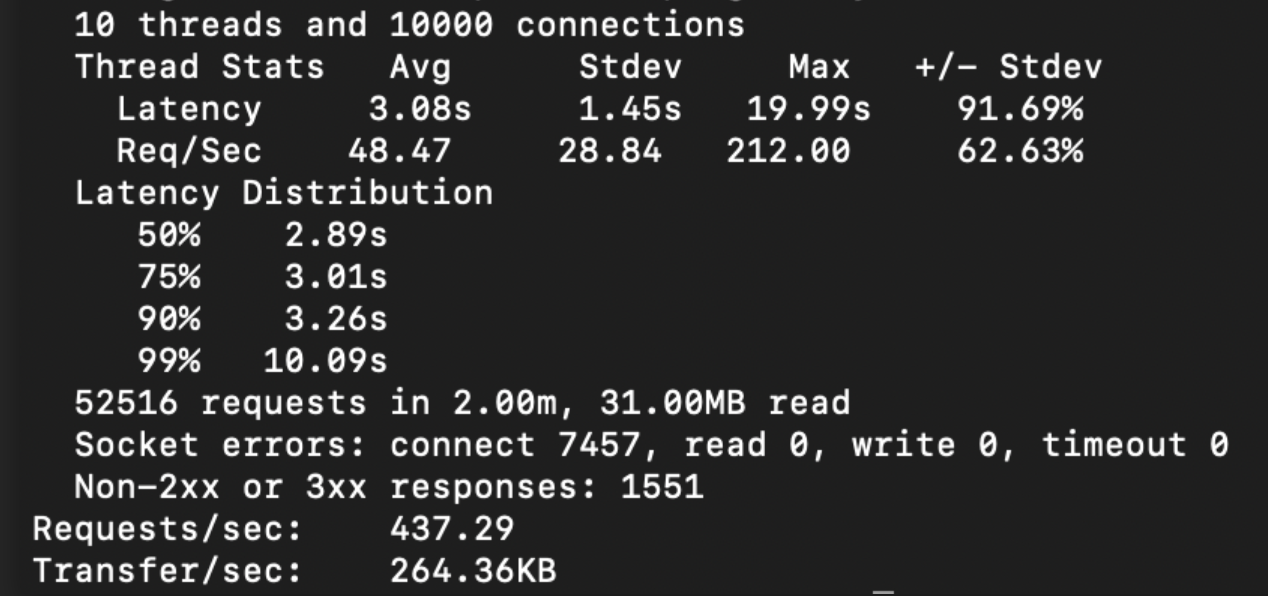 With Async Local Storage
With Async Local Storage

As can be seen from these tests, Async Local Storage performs super close to the original API with only a 2% impact.
Closing Points… Link to heading
Before I end this article, here are some things to consider:
- The Async Hooks feature is still experimental but still, it’s already being used on some well known products in production environments like kuzzle.io.
- The Async Local Storage was marked as stable in v16.4.0. It is preferred over Async Hooks.
Regardless, this is a huge plus point given the minimal performance impact and thus, is a must try!